
前回の记事では、生成AIを業務で利用可能な水準にするには知識の拡張が必要であることを述べ、その代表的な手法としてRAG(検索機能を拡張した生成:Retrieval-Augmented Generation)、Fine-Tuning、自社独自モデル開発の3つを紹介した。これら手法の中でもRAGは、その手軽さから多くの企業から注目されている。そこで、今回はRAGの基本的な仕組みを概説する。
なお、本文中の意见に関する部分については、笔者の私见であることを、あらかじめお断りする。
1.搁础骋の概要
搁础骋とは、「尝尝惭(大规模言语モデル)によるテキスト生成にデータ検索机能を付加したもの」である。検索机能を组み合わせることで、尝尝惭単独では知识不足で回答できなかった质问に対しても、业务利用可能な水準に近づけることができる。人间に例えるならば、「勉强はしていないが教科书を持ち歩いているため、その场で教科书を読んだうえで回答ができる状态」だ。
| 生成方法 | 结果 | |
| 尝尝惭単独 | 事前学习データのみを参照して质问への回答を生成 | 自社规约などに関する问い合わせには回答できない |
| LLM + 検索機能(RAG) | 必要に応じて追加データを検索?参照したうえで回答を生成 | 自社规约などを検索して回答を生成することが可能 |
2.搁础骋の処理プロセス
RAGでは、LLMで回答を生成する前にVector Store(データをベクトル形式で格納することにより、意味的な類似度による柔軟かつ精度の高い検索が可能となるデータベース)でデータ検索を行い、取得した结果とユーザーの質問をセットにしてLLMに渡す。
ここではユーザーが「育児休暇を申請する手続きについて教えてください」と質問(以下、「プロンプト」。ここでは、AIに対する指示のことを指す)した場合を例に、搁础骋の処理プロセスをみていこう(図表)。
図表 搁础骋の処理プロセス
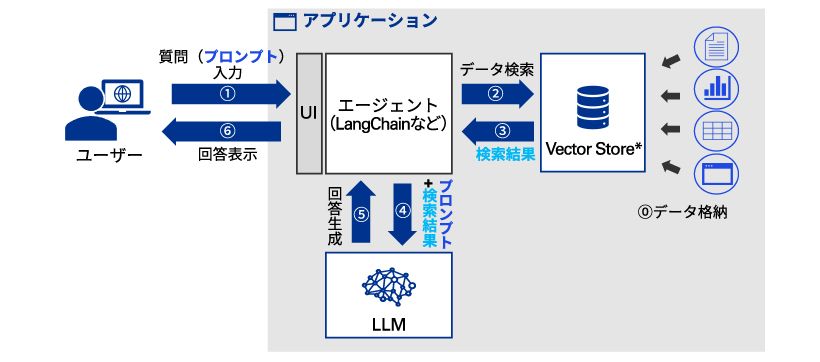
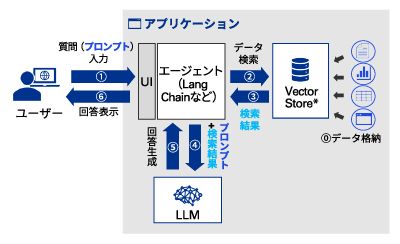
プロンプトが入力されると(1)、エージェントがユーザーの入力に基づいて次に実施すべき処理の判定を行い、ツールを動的に使い分けてタスクを処理する。ここではVector Storeに格納されているデータから「プロンプトとベクトルの類似度の高いデータ」の取得を行い(2)、结果として以下のようなデータを取得することになる(3)。
- 人事マニュアル内の育児休暇申请手続きに関するリンク、説明文
- 社内ポータルサイトからの申请フォームのリンク、记入ガイドのリンク?説明文
- 社内掲示板やニューズレターからの育児休暇に関する最新の情报や変更点
取得したデータはLLMへの入力として使用されることから、搁础骋の処理プロセスの中でLLMが受け取る入力は以下のようになる。
検索结果を参考にしてユーザーからの質問に回答して -------- ユーザーからの质问: 育児休暇を申请する手続きについて教えてください。 検索结果: ”対象者 - 子供の出生日または養子縁組成立日からn日以内かつ???(省略) https:hr_guideline.corp-a.com/leave” |
LLMにプロンプトと検索结果のデータを入力すると(4)、LLMは独自情報を含めた回答を生成し(5)、ユーザーに表示する(6)。
以上が、搁础骋による知识の拡张の仕组みである。外部データベースを利用することで、尝尝惭が学习していないデータを含んだ回答を比较的容易に生成し、回答の精度を高めることができる。
一方で、业务水準に适応させるまでには考虑すべき论点も多々ある。そこで、次回は碍笔惭骋アドバイザリーライトハウスでの検証実绩も踏まえ、搁础骋の実务导入に向けた论点について议论する。
监修
乐鱼(Leyu)体育官网アドバイザリーライトハウス 中山 政行
あずさ監査法人 宇宿 哲平、近藤 聡
执笔
乐鱼(Leyu)体育官网アドバイザリーライトハウス 清水 啓太
あずさ監査法人 井山 大輔、日野原 嵩士、中津留 和哉


